
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 투포인터
- 다익스트라
- 프로그래머스 #파이썬 #코딩테스트 #알고리즘
- 재귀
- react #리액트 #동빈나
- 프로그래머스 #파이썬 #알고리즘 #코딩테스트
- java #자바
- java #자바 #생활코딩
- 알고리즘
- 백준 #알고리즘 #파이썬 #코딩테스트
- BFS
- react #리액트 #동빈나 #나동빈 #유튜브강의
- Dijkstra
- 파이썬 #백준 #알고리즘 #코딩테스트
- 백준 #파이썬 #알고리즘 #코딩테스트
- PYTHON
- 백트랙킹
- 자바 #java
- 백준
- dp
- DFS
- 코딩테스트
- java #자바 #동빈나
- 다이나믹프로그래밍
- css #생활코딩 #웹
- java #자바 #나동빈
- 프로그래머스
- 파이썬
- css #웹 #생활코딩
- 파이썬 #알고리즘 #코딩테스트 #프로그래머스
Archives
- Today
- Total
커리까지
데이콘 - KBO 외국인 투수 스카우팅 최적화 경진대회 [연습]_03 본문
728x90
SMALL
- 그럼 구종이 다양하면서 단타 비율이 높고 키가 크면서 결정구를 가지고 커맨드가 좋은 선수를 뽑으면 되겠다.
- 그동안에 방출안된 선수들의 기록을 살펴보자.
- BABIP이 낮고, WAR이 높고, SwStr과 Swing이 높고 GB,FB,IFFB도 높은 순으로 찾아봐야겠다. 거기에 구종의 개수를 추가하자.
- 물론 세이브와 안타, 홈런, ERA도 고려해야 한다.
- kbo타자들이 어떤 공에 취약한지 찾아보고 그 공을 자주 던지는 선수를 찾아보자.
외국인스탯캐스터.groupby(['pitcher_name','pitch_name']).agg({'pitch_name':'count'})
- 이렇게 그동안의 구종을 종합해보았다.
외국인스탯캐스터.groupby(['pitcher_name','pitch_name']).agg({'pitch_name':'count'}).T['휠러']
- 2018년에 방출된 휠러선수의 기록이다. 확실히 다른 선수들보다 pitch가 적다. 이렇게 선수들의 기록을 딕셔너리 형식으로 담아서 컬럼에 저장하려고 한다.
df로 저장하기
- 일반선수와 방출되지 않은 선수들의 정보를 df로 만들었다.
mlb_data = pd.DataFrame({'pitcher_name':[], '2-Seam Fastball':[],'4-Seam Fastball':[],'Changeup':[],'Curveball':[],
'Cutter':[],'Intentional Ball':[],'Pitch Out':[],'Slider':[]})
for name in playername:
a = 외국인스탯캐스터.groupby(['pitcher_name','pitch_name']).agg({'pitch_name':'count'})\
.T[name].reset_index(drop=True)
a['pitcher_name'],a['cnt'] = name, a.shape[1]
mlb_data = mlb_data.append(a,ignore_index=True)
mlb_data - 빈 df를 만들어서 계속 붙여나갔다.

- 방출되지 않은 선수 df
not_out = list(filter(lambda x:x not in playername,list(throw_df.drop_duplicates(['pitcher_name'])['pitcher_name'])))
mlb_data_2 = pd.DataFrame({'pitcher_name':[], '2-Seam Fastball':[],'4-Seam Fastball':[],'Changeup':[],'Curveball':[],
'Cutter':[],'Intentional Ball':[],'Pitch Out':[],'Slider':[]})
for name in not_out:
a = 외국인스탯캐스터.groupby(['pitcher_name','pitch_name']).agg({'pitch_name':'count'})\
.T[name].reset_index(drop=True)
a['pitcher_name'],a['cnt'] = name, a.shape[1]
mlb_data_2 = mlb_data.append(a,ignore_index=True)
mlb_data_2 - 그러나 다음과 같은 에러가 발생하였다.
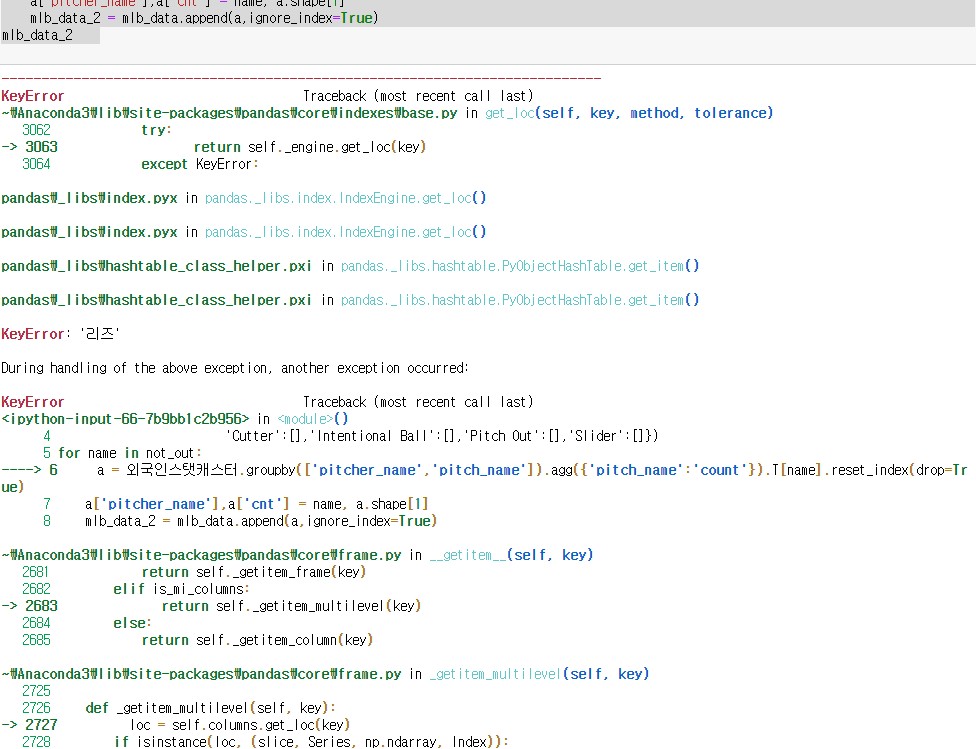
- 외국인스탯캐스터에 정보가 없는 선수들이 있었다.
- 그래서 try와 except를 하였다.
not_out = list(filter(lambda x:x not in playername,list(throw_df.drop_duplicates(['pitcher_name'])['pitcher_name'])))
mlb_data_2 = pd.DataFrame({'pitcher_name':[], '2-Seam Fastball':[],'4-Seam Fastball':[],'Changeup':[],'Curveball':[],
'Cutter':[],'Intentional Ball':[],'Pitch Out':[],'Slider':[]})
for name in not_out:
try:
a = 외국인스탯캐스터.groupby(['pitcher_name','pitch_name']).agg({'pitch_name':'count'})\
.T[name].reset_index(drop=True)
a['pitcher_name'],a['cnt'] = name, a.shape[1]
mlb_data_2 = mlb_data_2.append(a,ignore_index=True)
except:
print(name)
mlb_data_2 - 리즈와 카스티요선수만 없었다.

7~8개를 가진 선수들이 많다.
이 정보와 함께 x,y축을 이용한 캐글 코드를 사용하려고 한다. 출처

- 이렇게 스트라이크 존을 예측해준다. 따라해보자.
def plot_SVM(aaron_judge,gamma=1, C=1):
# aaron_judge = pd.read_csv('../input/aaron_judge.csv')
#print(aaron_judge.columns)
#print(aaron_judge.description.unique())
#print(aaron_judge.type.unique())
aaron_judge.type = aaron_judge.type.map({'S':1, 'B':0})
#print(aaron_judge.type)
#print(aaron_judge['plate_x'])
aaron_judge = aaron_judge.dropna(subset = ['type', 'plate_x', 'plate_z'])
fig, ax = plt.subplots()
plt.scatter(aaron_judge.plate_x, aaron_judge.plate_z, c = aaron_judge.type, cmap = plt.cm.coolwarm, alpha=0.6)
training_set, validation_set = train_test_split(aaron_judge, random_state=1)
classifier = SVC(kernel='rbf', gamma = gamma, C = C)
classifier.fit(training_set[['plate_x', 'plate_z']], training_set['type'])
draw_boundary(ax, classifier)
plt.show()
print("The score of SVM with gamma={0} and C={1} is:".format(gamma, C) )
print(classifier.score(validation_set[['plate_x', 'plate_z']], validation_set['type']))aaron_judge.type = aaron_judge.type.map({'S':1, 'B':0})여기를 보면 스트라이크와 볼이 다른 값을 가져야 한다. 그래서 밑에 사진과 같이 같은 타자에게 누적된 값을 분리해줘야 하는 작업이 필요하다.

ball, strike를 입력하기
외국인스탯캐스터_ball = 외국인스탯캐스터.sort_values(by=['game_date','pitcher','batter','balls']).reset_index(drop=True)
외국인스탯캐스터_strikes = 외국인스탯캐스터.sort_values(by=['game_date','pitcher','batter','strikes']).reset_index(drop=True)
외국인스탯캐스터.head()- 볼로 정렬한것과 스트라이크로 정렬한거 2개 df를 만들기
for i in range(1,외국인스탯캐스터_ball.shape[0]):
if 외국인스탯캐스터_ball.loc[i-1,'batter'] == 외국인스탯캐스터_ball.loc[i,'batter'] and\
외국인스탯캐스터_ball.loc[i-1,'pitcher'] == 외국인스탯캐스터_ball.loc[i,'pitcher']:
ball_cnt = 외국인스탯캐스터.loc[i,'balls'] - 외국인스탯캐스터.loc[i-1,'balls']
print(f'ball_cnt, : {ball_cnt}')
- 이렇게 볼과 스트라이크를 새로운 컬럼으로 만들어보자.
- 다시보니 원래 데이터가 정렬이 되어있어서 그걸 기준으로 잡고 다시 만들었다.
for i in range(외국인스탯캐스터.shape[0]-1):
if 외국인스탯캐스터.loc[i,'batter'] == 외국인스탯캐스터.loc[i+1,'batter'] and\
외국인스탯캐스터.loc[i,'pitcher'] == 외국인스탯캐스터.loc[i+1,'pitcher']:
ball_cnt = 외국인스탯캐스터.loc[i,'balls'] - 외국인스탯캐스터.loc[i+1,'balls']
strike_cnt = 외국인스탯캐스터.loc[i,'strikes'] - 외국인스탯캐스터.loc[i+1,'strikes']
print(f'ball_cnt : {ball_cnt}, strike_cnt : {strike_cnt}')
if ball_cnt == 1: 외국인스탯캐스터.loc[i,'type'] = 0
if strike_cnt == 1:외국인스탯캐스터.loc[i,'type'] = 1
- type의 숫자를 한칸씩 뒤로 밀어야 한다. 이렇게 하니깐 맨 마지막 공을 판단 하기 어려워서 description에 나와있는 설명으로 판단하는게 나을것 같다.
strike와 ball 분리하기
from tqdm import tqdm
for i in tqdm(range(외국인스탯캐스터.shape[0])):
if 외국인스탯캐스터.loc[i,'description'].split('_')[-1] in ['strike','foul']:
외국인스탯캐스터.loc[i,'type'] = 'S'
elif 외국인스탯캐스터.loc[i,'description'].split('_')[-1] in ['ball']:
외국인스탯캐스터.loc[i,'type'] = 'B'
else:
외국인스탯캐스터.loc[i,'type'] = 'N'

- description에 나와있는 설명을 기준으로 strike와 foul은 strike로 ball은 ball로 분리하고 두가지 모두 아니면 출루, 득점, 아웃이기때문에 우선은 제외하였다. rmse가 낮으면 스트라이크로 추가해서 다시 돌려본다. 우선은 제외하고 진행한다.

- 이렇게 만든다.
외국인스탯캐스터_index = list(외국인스탯캐스터[외국인스탯캐스터['type'] == 'N'].index)
외국인스탯캐스터_index
외국인스탯캐스터_filter = 외국인스탯캐스터.drop(외국인스탯캐스터_index).reset_index(drop=True)
외국인스탯캐스터_filter- N인 것들은 우선 제외하고 다시 df를 만든다.
캐글에 나와있는 스타라이크 존 SVM 해보기[https://www.kaggle.com/jzdsml/sp-finding-baseball-strike-zone-w-svm]
def make_meshgrid(ax, h=.02):
x_min, x_max = ax.get_xlim()
y_min, y_max = ax.get_ylim()
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
return xx, yy
def plot_contours(ax, clf, xx, yy, **params):
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
out = ax.contourf(xx, yy, Z, **params)
return out
def draw_boundary(ax, clf):
xx, yy = make_meshgrid(ax)
return plot_contours(ax, clf, xx, yy,cmap=plt.cm.coolwarm, alpha=0.5)from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
def plot_SVM(aaron_judge,gamma=1, C=1):
aaron_judge.type = aaron_judge.type.map({'S':1, 'B':0})
fig, ax = plt.subplots()
plt.scatter(aaron_judge.plate_x, aaron_judge.plate_z, c = aaron_judge.type, cmap = plt.cm.coolwarm, alpha=0.6)
training_set, validation_set = train_test_split(aaron_judge, random_state=1)
classifier = SVC(kernel='rbf', gamma = gamma, C = C)
classifier.fit(training_set[['plate_x', 'plate_z']], training_set['type'])
draw_boundary(ax, classifier)
plt.show()
print("The score of SVM with gamma={0} and C={1} is:".format(gamma, C) )
print(classifier.score(validation_set[['plate_x', 'plate_z']], validation_set['type']))
- 표본이 적어서 그런지 엄청나게 잘 예측하였다.
svc가 무엇인지, 매게변수가 어떤의미를 가지는지 알아보기
선수별로 SVM은 나중에 구해보고 리포트에 나와있는 경기의 승패를 찾아서 학습하기
- 스탯캐스터에서는 구종이랑 평균 구속, 좌타와 우타에 대한 스트라이크, 볼의 개수만 가져와서 한국 스탯이랑 합쳐야겠다.
외국인스탯캐스터.to_csv('최종외국인스탯캐스터.csv', encoding='euc-kr',index = False)- 위에서 만들었던 파일을 저장하여 이 파일로 이제 활용하자.
728x90
LIST
'프로젝트 > KBO 외국인 투수 스카우팅 최적화 경진대회' 카테고리의 다른 글
| 데이콘 - KBO 외국인 투수 스카우팅 최적화 경진대회 [연습]_04 (0) | 2021.04.02 |
|---|---|
| [SVM] 서포트 백터 머신이란? (0) | 2021.03.19 |
| 데이콘 - KBO 외국인 투수 스카우팅 최적화 경진대회 [연습]_02 (0) | 2021.01.19 |
| 파이썬 문자열을 변수로 호출하기 (0) | 2021.01.10 |
| 데이콘 - KBO 외국인 투수 스카우팅 최적화 경진대회 [연습] (0) | 2021.01.04 |
'프로젝트/KBO 외국인 투수 스카우팅 최적화 경진대회' Related Articles
more

Comments