영화추천 프로젝트 02
4. 알고리즘 별 cross_validate
이번에도 팀원 당 1개씩 알고리즘을 찾고 실행해보기로 하였다.
알고리즘 별로 성능을 비교하였다.
data = Dataset.load_from_df(df[['userId', 'movieId', 'rating']], reader)
svd = SVD()
slope = SlopeOne()
nmf = NMF()
bsl_options = {'method': 'als',
'n_epochs': 5,
'reg_u': 12,
'reg_i': 5
}
als = BaselineOnly(bsl_options=bsl_options)
als_result = cross_validate(als, data, measures=['RMSE', 'MAE'],cv=5, verbose=False)
slope_result = cross_validate(slope, data, measures=['RMSE', 'MAE'],cv=5, verbose=False)
svd_result = cross_validate(svd, data, cv = 5, measures=['RMSE', 'MAE']) #evaluate 대신
nmf_result = cross_validate(nmf, data, measures=['RMSE', 'MAE'],cv=5, verbose=False)
- 위에서 만들어놓은
df를Dataset.load_from_df로Pandas Dataframe으로 로딩한다. - 각각에 알고리즘을 불러와서 알고리즘 이름에 할당한다.
cross_validate로 4개의 알고리즘을 비교하는 변수를 만든다.
알고리즘 분석
(1) SVD
특잇값 분해 (singular value decomposition)라고 한다.
0이 많은 행렬을 이용하여 예측값을 구한다.
- SVD를 통해 차원을 축소시킨다.
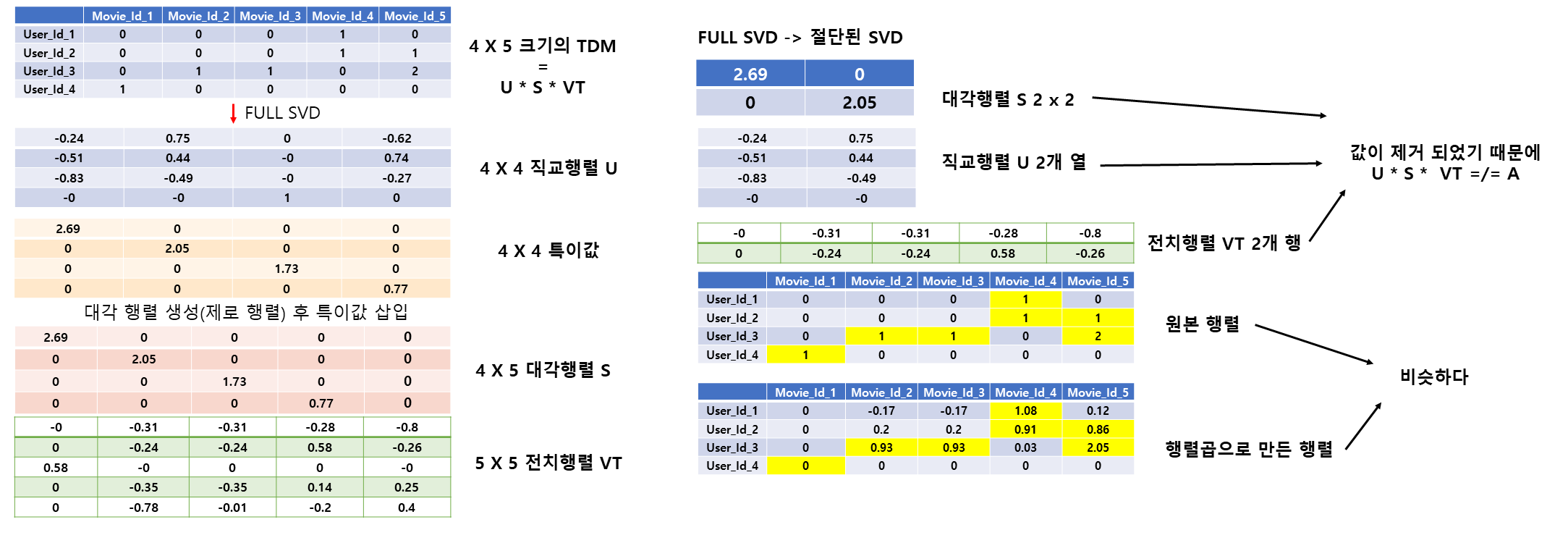
- 자료를 참고하여 만들었기 때문에 평점이 1과 2로 구성되어 있다.
- 평점을 U, S, VT 로 나누어서 FULL SVD 를 만들고 절단된 SVD 를 만들어서 최종 예측값을 구한다.
(2) SlpoeOne
- 새로운 아이템과 다른 아이템의 사용자 선호의 평균적인 값의 차이에 기반해서 새로운 선호를 추정하는 것이다. (http://wiki.gurubee.net/pages/viewpage.action?pageId=28118045)
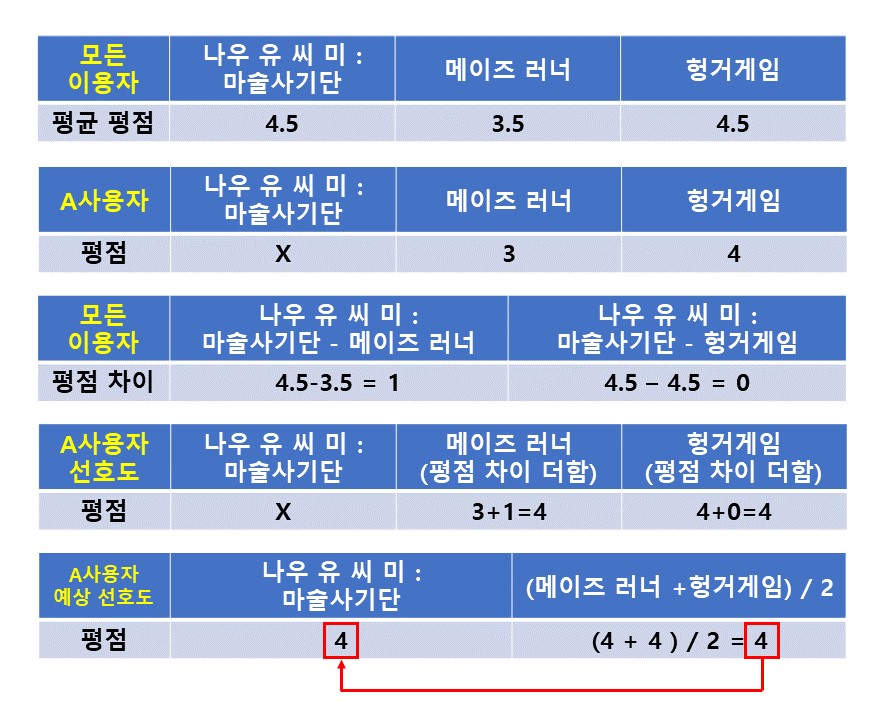
그림과 같이 A사용자에게 나우 유 씨 미 : 마술사긴단의 선호도를 구하기 위해 slope-one을 적용하면 다음과 같다.
모든 이용자의 영화 평점에서 나우 유 씨 미 : 마술사기단 이 메이즈 러너 의 평점보다 평균 1.0 높다.
나우 유 씨 미 : 마술사기단 과 헝거게임 의 평점 평균은 같다.
A사용자의 메이즈 러너 평점에 평균 차이 1.0 을 더해주고, 헝거에임 평점에 평균차이 0 을 더하여 선호도를 구한다.
2개의 선호도를 더해 2로 나누면 A사용자의 나우 유 씨 미 : 마술사기단 의 예상 선호도를 구할 수 있다.
- 이 값이 SLOPE-ONE 이 추천해주는 값이다.
(3) ALS
- Alaternating Least Squares의 약자로 교대 최소 제곱법이라고도 한다.
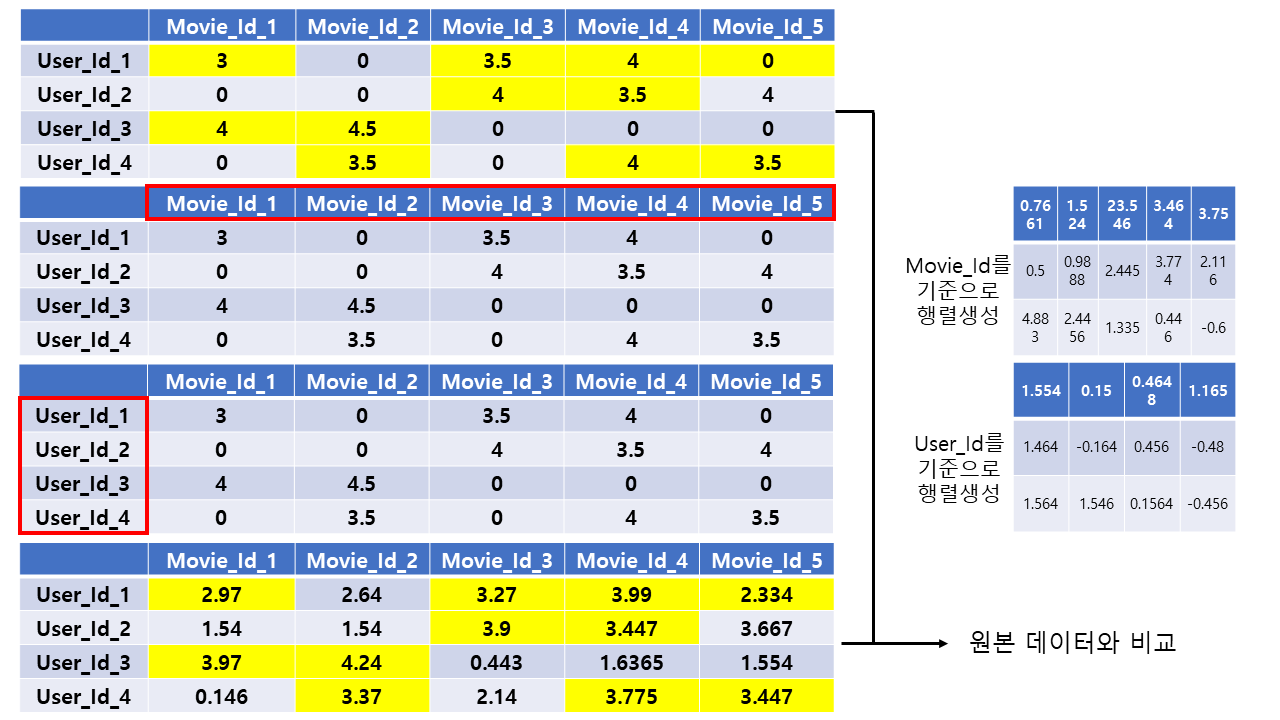
두 행렬을 한 번에 최적하기 어렵기 때문에
Movie_Id를 고정 시킨 후User_Id를 학습시키고,User_Id를 고정시키고Movie_Id를 학습시킨다.- 사용자가 정한 개수만큼 돌려서 최적화 값을 구한다.
(4) NMF
비음수 행렬 분해(Non-negative Matrix Factorization) 라고도 한다.
- 음수가 포함되지 않은, 전체 원소가 양수인 행렬 V를 음수를 포함하지 않는 행렬 W와 H의 곱으로 분해하는 알고리즘이다. (https://kolikim.tistory.com/28)
- 독립 특성 추출 기법중 하나 자료 참고 사이트
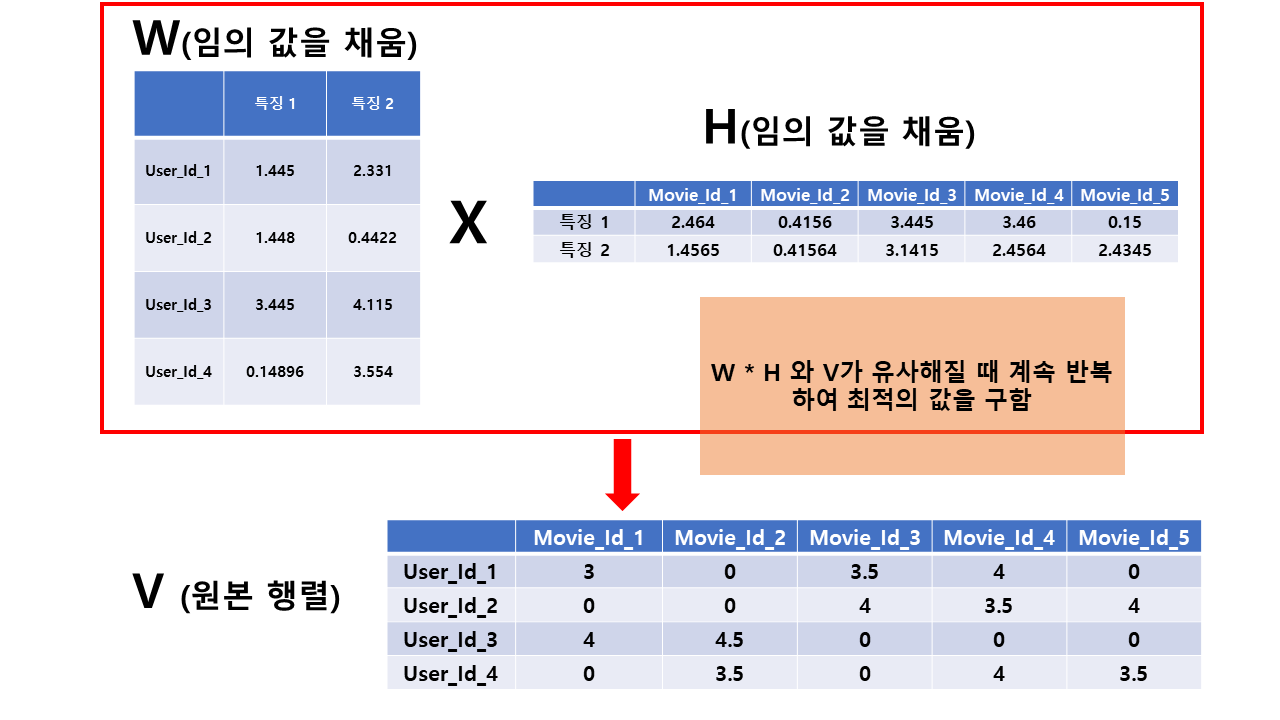
원본 행렬과 유사할 때 까지 인수분해 알고리즘을 반복한다.
WxH값이 나중에 최종 예측치가 된다.
5. 알고리즘에 따른 RMSE, MAE 비교
print(slope_result)
print(svd_result)
print(nmf_result)
print(als_result)
{'test_rmse': array([0.87953958, 0.88650737, 0.87635314, 0.88262746, 0.8591474 ]), 'test_mae': array([0.67374703, 0.676835 , 0.67501659, 0.68241775, 0.66127178]), 'fit_time': (1.2840924263000488, 1.3566598892211914, 1.267472743988037, 1.256450891494751, 1.2587716579437256), 'test_time': (4.198052167892456, 4.224506139755249, 4.2405617237091064, 4.183813571929932, 4.232964992523193)}
{'test_rmse': array([0.85395005, 0.87125244, 0.86363435, 0.86995815, 0.87245622]), 'test_mae': array([0.65569904, 0.67017291, 0.66406423, 0.66888591, 0.67280715]), 'fit_time': (3.0986475944519043, 3.110785484313965, 3.136587381362915, 3.1339731216430664, 3.125138521194458), 'test_time': (0.08710980415344238, 0.17372965812683105, 0.08742976188659668, 0.08999967575073242, 0.0852959156036377)}
{'test_rmse': array([0.90203039, 0.90187266, 0.89416603, 0.89548174, 0.88277262]), 'test_mae': array([0.6956759 , 0.69435815, 0.69261027, 0.68884812, 0.68265735]), 'fit_time': (3.246049165725708, 3.2357935905456543, 3.2534329891204834, 3.2536609172821045, 3.263439893722534), 'test_time': (0.09050822257995605, 0.07431292533874512, 0.0717926025390625, 0.07917928695678711, 0.07118105888366699)}
{'test_rmse': array([0.86385979, 0.86430665, 0.84987961, 0.85024716, 0.85725621]), 'test_mae': array([0.66585506, 0.66623912, 0.65413453, 0.65648521, 0.65778627]), 'fit_time': (0.07578492164611816, 0.08110427856445312, 0.0884253978729248, 0.081146240234375, 0.08066868782043457), 'test_time': (0.05817055702209473, 0.05798792839050293, 0.12647652626037598, 0.06371307373046875, 0.057706594467163086)}
- 4개의 알고리즘마다
'test_rmse','test_mae','fit_time','test_time'을 비교한다. 5개로 나누었기 때문에 한 알고리즘마다 5개의 값이 나온다.
6. 유저에 따른 개인 영화 추천
user_id에 따라 영화 추천을 해준다. user_id에 따라 영화가 바뀌는지 알아보자.
meta['genres'] = meta['genres'].apply(parse_genres)
genres가 제이슨 형식이기 때문에 장르만 빼오기 위하여 위에서 만든 함수를 실행한다.
def user_difference(data,usernumber,rating,moviedata,dropdata,reader,svd):
df = data
df_user = df[(df['userId'] == usernumber) & (df['rating'] == rating)]
df_user = df_user.set_index('movieId')
df_user = df_user.join(moviedata)['original_title']
print(df_user)
user_release_ratio_list = user_release_ratio(df, usernumber)
user_df = moviedata.copy()
user_df = user_df[~user_df['movieId'].isin(dropdata)]
data1 = Dataset.load_from_df(df[['userId', 'movieId', 'rating']], reader)
trainset = data1.build_full_trainset()
svd.fit(trainset)
user_df['Estimate_Score'] = user_df['movieId'].apply(lambda x: svd.predict(usernumber, x).est)
user_df = user_df.sort_values('Estimate_Score', ascending=False)
print(user_df.head(10))
return user_df
user_df665 = user_difference(df,665,5,meta,drop_movie_list,reader,svd)
user_df664 = user_difference(df,664,5,meta,drop_movie_list,reader,svd)
df를 불러와서user_id와ratings에 입력한 값과 같은 영화들만 뽑아서movieId를index로 지정하고movies_metadata에 있는movieId와 비교하여original_title을 join해서 제목을 연결해준다.- 위에서 만들어 놓은
개봉일 함수를 실행한다. movies_metadata을 위에서 만들었던drop_movie_list에 값이 없는 것들을 다시 저장 하고svd()로 예측값을user_df에 새로운 컬럼으로 저장해준다.Estimate_Score값이 높은 순서대로 10개의 영화를 보여준다.
print(user_df665.iloc[0:12,[0,1,6]])
movieId original_title Estimate_Score
5295 4993.0 5 Card Stud 4.647323
11922 2959.0 License to Wed 4.546697
4020 318.0 The Million Dollar Hotel 4.538210
37719 58559.0 Confession of a Child of the Century 4.518721
2649 912.0 The Thomas Crown Affair 4.474818
534 858.0 Sleepless in Seattle 4.449768
286 527.0 Once Were Warriors 4.410385
7727 246.0 座頭市 4.345436
8316 905.0 Die Büchse der Pandora 4.309588
33913 3578.0 Der Tunnel 4.295514
2533 3035.0 Frankenstein 4.262311
6924 916.0 Bullitt 4.230835
- 이렇게 영화를 추천해준다.
print(user_df664.iloc[0:12,[0,1,6]])
movieId original_title Estimate_Score
3058 926.0 Galaxy Quest 4.584223
6836 899.0 Broken Blossoms 4.555982
534 858.0 Sleepless in Seattle 4.528558
11922 2959.0 License to Wed 4.526900
14332 2973.0 Аэлита 4.488915
6388 296.0 Terminator 3: Rise of the Machines 4.485133
938 260.0 The 39 Steps 4.476559
8316 905.0 Die Büchse der Pandora 4.464822
33913 3578.0 Der Tunnel 4.464652
22347 5995.0 Miffo 4.462038
11566 1252.0 Lonely Hearts 4.438819
11911 2359.0 Sicko 4.437585
- 서로 영화 추천이 다른것을 볼 수 있다.
7. 유저의 변화에 따른 영화추천
위 유저영화추천 이랑 다른점은 유저가 본 영화를 추가 를 시켜서 다시 추천해주는 것이다.
def user_difference(data,usernumber,rating,moviedata,dropdata,reader,svd):
df = data
df_user = df[(df['userId'] == usernumber) & (df['rating'] == rating)]
df_user = df_user.set_index('movieId')
df_user = df_user.join(moviedata)['original_title']
print(df_user)
user_release_ratio_list = user_release_ratio(df, usernumber) # 유저의 년도 비율을 가져온다.
user_df = moviedata.copy()
user_df = user_df[~user_df['movieId'].isin(dropdata)]
data1 = Dataset.load_from_df(df[['userId', 'movieId', 'rating']], reader)
trainset = data1.build_full_trainset()
svd.fit(trainset)
user_df['Estimate_Score'] = user_df['movieId'].apply(lambda x: svd.predict(usernumber, x).est)
# user_df = user_df.drop('movieId', axis = 1)
user_df = user_df.sort_values('Estimate_Score', ascending=False)
print(user_df.head(10))
return user_df
user_1 = user_difference(df,1,5,meta,drop_movie_list,reader,svd)
df2 = df
df2.loc[1] = [1,5502,5.0]
df2.loc[2] = [1,5991.0,5.0]
add_user_1 = user_difference(df2,1,5,meta,drop_movie_list,reader,svd)
- 1차로 유저에게 영화를 추천해준다.
df2.loc[1] = [1,5502,5.0]와df2.loc[2] = [1,5991.0,5.0]를 통해User 1번에게 영화를 보았다고 하고 정보를 추가해준다.- 업데이트 된 정보로 다시 영화를 추천해준다.
- 1차 추천
movieId ... Estimate_Score
11566 1252.0 ... 4.430196
534 858.0 ... 4.410671
4020 318.0 ... 4.363900
2649 912.0 ... 4.356379
6388 296.0 ... 4.321805
2648 913.0 ... 4.318723
22347 5995.0 ... 4.292384
3058 926.0 ... 4.283055
10089 953.0 ... 4.275556
6836 899.0 ... 4.271212
- 2차 추천
movieId ... Estimate_Score
700 922.0 ... 4.850050
2648 913.0 ... 4.818520
3058 926.0 ... 4.704037
2888 2020.0 ... 4.634826
9758 4235.0 ... 4.628784
6836 899.0 ... 4.618937
534 858.0 ... 4.614157
7727 246.0 ... 4.598594
3059 1213.0 ... 4.598093
29151 46578.0 ... 4.587330
- 다른 영화를 추천해주는 것을 볼 수 있다.
8. 변수 가중치에 따른 영화 추천
위에서 우리 팀이 만들어 놓았던 가중치 함수를 실행하여 변수에 따라 영화추천이 어떻게 바뀌는 지 비교해본다.
def variable_weight(data,usernumber,rating,moviedata,dropdata,reader,algo):
df = data
df_user = df[(df['userId'] == usernumber) & (df['rating'] == rating)]
df_user = df_user.set_index('movieId')
df_user = df_user.join(moviedata)['original_title']
# print(df_user)
user_release_ratio_list = user_release_ratio(df, usernumber)
# print(user_release_ratio_list)
user_pop_ratio_list = user_pop_ratio(df, usernumber)
# print(user_pop_ratio_list)
user_language_ratio_list = user_language_ratio(df, usernumber)
# print(user_language_ratio_list)
user_df = moviedata.copy()
user_df = user_df[~user_df['movieId'].isin(dropdata)]
data1 = Dataset.load_from_df(df[['userId', 'movieId', 'rating']], reader)
trainset = data1.build_full_trainset()
algo.fit(trainset)
user_df['Estimate_Score'] = user_df['movieId'].apply(lambda x: algo.predict(usernumber, x).est)
# user_df = user_df.drop('movieId', axis = 1)
user_df = user_df.sort_values('Estimate_Score', ascending=False)
# print(user_df.head(10))
user_df_sum = Estimate_Score_sum1(user_df, user_release_ratio_list)
user_df_sum_relase = user_df_sum.sort_values('Estimate_Score', ascending=False)
print("개봉일 별 가중치")
print(user_df_sum_relase.head(10))
user_df_sum = Estimate_Score_sum2(user_df, user_pop_ratio_list)
user_df_sum_pop = user_df_sum.sort_values('Estimate_Score', ascending=False)
print("인기 별 가중치")
print(user_df_sum_pop.head(10))
user_df_sum = Estimate_Score_sum3(user_df, user_language_ratio_list)
user_df_sum_lang = user_df_sum.sort_values('Estimate_Score', ascending=False)
print("언어 별 가중치")
print(user_df_sum_lang.head(10))
return user_df_sum_relase, user_df_sum_pop, user_df_sum_lang
user_df_sum_relase,user_df_sum_pop, user_df_sum_lang = variable_weight(df,665,5,meta,drop_movie_list,reader,svd)
user_df_sum_relase에는 개봉일 변수,user_df_sum_pop에는 인기변수,user_df_sum_lang에는 언어 변수가 들어있다.
vote_data, vote_meta = user_vote_ratio()
- vote 가중치를 주기위해 먼저 데이터를 다시 정비한다.
def variable_weight2(data,usernumber,rating,moviedata):
df = data.copy()
df_user = df[(df['userId'] == usernumber) & (df['rating'] == rating)]
df_user = df_user.set_index('movieId')
# print(df_user.iloc[:,2]) #제가 만든 meta에 이미 title이 있어서join을 할 필요가 없었습니다.
user_df = moviedata.copy()
user_df = user_df[~user_df['movieId'].isin(drop_movie_list)]
data1 = Dataset.load_from_df(df[['userId', 'movieId', 'rating']], reader)
trainset = data1.build_full_trainset()
svd.fit(trainset)
user_df['Estimate_Score'] = user_df['movieId'].apply(lambda x: svd.predict(usernumber, x).est)
user_df.reset_index(inplace=True, drop=True)
Estimate_Score_sum4(df_user,user_df)
# user_df = user_df.drop('movieId', axis = 1)
user_df = user_df.sort_values(('Estimate_Score'), ascending=False)
user_df_sum_vote = pd.DataFrame(user_df)
user_df_sum_vote = user_df_sum_vote.iloc[:,[0,1,3,4,5,8]]
return user_df_sum_vote
user_df_sum_vote = variable_weight2(vote_data,665,5,vote_meta)
- 개봉일 변수 가중치 영화 추천
movieId original_title ... original_language Estimate_Score
286 527.0 Once Were Warriors ... en 4.671092
43368 48780.0 Boat ... en 4.663926
6910 898.0 Birdman of Alcatraz ... en 4.654574
11566 1252.0 Lonely Hearts ... en 4.640641
11355 3683.0 Flags of Our Fathers ... en 4.572242
10089 953.0 Madagascar ... en 4.569152
4020 318.0 The Million Dollar Hotel ... en 4.554524
3058 926.0 Galaxy Quest ... en 4.551128
6714 1584.0 School of Rock ... en 4.550321
22347 5995.0 Miffo ... sv 4.541303
- 인기 변수 가중치 영화 추천
movieId original_title ... original_language Estimate_Score
6910 898.0 Birdman of Alcatraz ... en 4.796574
286 527.0 Once Were Warriors ... en 4.660092
2100 2762.0 Young and Innocent ... en 4.614641
5295 4993.0 5 Card Stud ... en 4.606212
33913 3578.0 Der Tunnel ... de 4.601541
2649 912.0 The Thomas Crown Affair ... en 4.585195
2533 3035.0 Frankenstein ... en 4.553614
4020 318.0 The Million Dollar Hotel ... en 4.543524
11566 1252.0 Lonely Hearts ... en 4.508641
938 260.0 The 39 Steps ... en 4.507281
- 언어 변수 가중치 영화 추천
movieId original_title ... original_language Estimate_Score
6910 898.0 Birdman of Alcatraz ... en 5.408574
286 527.0 Once Were Warriors ... en 5.272092
5295 4993.0 5 Card Stud ... en 5.253212
2649 912.0 The Thomas Crown Affair ... en 5.227195
2100 2762.0 Young and Innocent ... en 5.226641
2533 3035.0 Frankenstein ... en 5.195614
4020 318.0 The Million Dollar Hotel ... en 5.155524
3058 926.0 Galaxy Quest ... en 5.152128
43368 48780.0 Boat ... en 5.143926
11566 1252.0 Lonely Hearts ... en 5.120641
- 평점과 투표수 변수 가중치 영화 추천
movieId original_title vote_average vote_count genres Estimate_Score
259 527 Once Were Warriors 7.6 106 [Drama] 4.693540
3634 318 The Million Dollar Hotel 5.9 76 [Drama, Thriller] 4.539169
32156 3578 Der Tunnel 6.5 2 [Science Fiction] 4.504137
10925 2959 License to Wed 5.3 258 [Comedy] 4.467404
4808 4993 5 Card Stud 6.0 20 [Action, Western, Thriller] 4.464193
299 2064 While You Were Sleeping 6.5 340 [Comedy, Drama, Romance] 4.406030
5835 296 Terminator 3: Rise of the Machines 5.9 2177 [Action, Thriller, Science Fiction] 4.404364
1098 910 The Big Sleep 7.6 244 [Crime, Drama, Mystery, Thriller] 4.399689
2363 912 The Thomas Crown Affair 6.9 95 [Romance, Crime, Thriller, Drama] 4.387938
6439 778 Les Vacances de Monsieur Hulot 7.3 76 [Comedy, Family] 4.380918
- 변수 가중치마다 영화 추천이 다르다. 추쳔 영화가 겹치지만 순위가 다른 점을 알 수 있다.
9. 알고리즘에 따른 영화 추천
SVD, SLOPE-ONE, ALS, NMF에 따른 영화 추천을 비교해본다.
def userRec3(data,usernumber,rating,moviedata,dropdata,reader,algo):
df = data
df_user = df[(df['userId'] == usernumber) & (df['rating'] == rating)]
df_user = df_user.set_index('movieId')
df_user = df_user.join(moviedata)['original_title']
# print(df_user)
user_release_ratio_list = user_release_ratio(df, usernumber)
# print(user_release_ratio_list)
user_pop_ratio_list = user_pop_ratio(df, usernumber)
# print(user_pop_ratio_list)
user_language_ratio_list = user_language_ratio(df, usernumber) .
# print(user_language_ratio_list)
user_df = moviedata.copy()
user_df = user_df[~user_df['movieId'].isin(dropdata)]
data1 = Dataset.load_from_df(df[['userId', 'movieId', 'rating']], reader)
trainset = data1.build_full_trainset()
algo.fit(trainset)
user_df['Estimate_Score'] = user_df['movieId'].apply(lambda x: algo.predict(usernumber, x).est)
# user_df = user_df.drop('movieId', axis = 1)
user_df = user_df.sort_values('Estimate_Score', ascending=False)
# print(user_df.head(10))
# user_df_sum = Estimate_Score_sum1(user_df, user_release_ratio_list)
# # user_df_sum = user_df_sum.sort_values('Estimate_Score', ascending=False)
# # print(user_df_sum.head(10))
# user_df_sum = Estimate_Score_sum2(user_df_sum, user_pop_ratio_list)
# # user_df_sum = user_df_sum.sort_values('Estimate_Score', ascending=False)
# # print(user_df_sum.head(10))
# user_df_sum = Estimate_Score_sum3(user_df_sum, user_language_ratio_list)
# user_df_sum = user_df_sum.sort_values('Estimate_Score', ascending=False)
# print(user_df_sum.head(10))
return user_df
als_recomend = userRec3(df,665,5,meta,drop_movie_list,reader,als)
svd_recomend = userRec3(df,665,5,meta,drop_movie_list,reader,svd)
slope_recomend = userRec3(df,665,5,meta,drop_movie_list,reader,slope)
nmf_recomend = userRec3(df,665,5,meta,drop_movie_list,reader,nmf)
알고리즘 별 cross_validate에서 만들었던 알로리즘 함수들을 적용시켜 영화 추천을 한다.
print(als_recomend)
print(svd_recomend)
print(slope_recomend)
print(nmf_recomend)
- ALS 알고리즘 영화 추천
movieId original_title ... original_language Estimate_Score
534 858.0 Sleepless in Seattle ... en 4.366613
11566 1252.0 Lonely Hearts ... en 4.327503
4020 318.0 The Million Dollar Hotel ... en 4.298712
2649 912.0 The Thomas Crown Affair ... en 4.276536
6388 296.0 Terminator 3: Rise of the Machines ... en 4.263070
... ... ... ...
11993 2701.0 Abraham ... en 2.165174
19332 1556.0 薔薇の葬列 ... ja 2.148789
1207 829.0 Chinatown ... en 2.046697
3293 2383.0 L'Ours ... en 2.012274
11324 3593.0 Dr. Cyclops ... en 1.789518
- SVD 알고리즘 영화 추천
movieId original_title ... original_language Estimate_Score
5295 4993.0 5 Card Stud ... en 4.666428
2649 912.0 The Thomas Crown Affair ... en 4.525694
11922 2959.0 License to Wed ... en 4.511459
278 1945.0 Nell ... en 4.497734
938 260.0 The 39 Steps ... en 4.471602
... ... ... ... ... ...
1391 784.0 Kolja ... cs 2.136321
7718 435.0 The Day After Tomorrow ... en 2.075654
11324 3593.0 Dr. Cyclops ... en 2.072793
990 173.0 20,000 Leagues Under the Sea ... en 2.061346
11993 2701.0 Abraham ... en 2.039181
- SLOPE-ONE 알고리즘 영화 추천
movieId original_title ... original_language Estimate_Score
7055 3022.0 Dr. Jekyll and Mr. Hyde ... en 4.862011
415 306.0 Beverly Hills Cop III ... en 4.795484
915 1939.0 Laura ... en 4.755736
16351 1361.0 The Return of the King ... en 4.705989
927 3083.0 Mr. Smith Goes to Washington ... en 4.679046
... ... ... ... ... ...
10582 2153.0 The Driver ... en 1.269766
3293 2383.0 L'Ours ... en 1.237044
32098 4255.0 The Party at Kitty and Stud's ... en 1.105735
11324 3593.0 Dr. Cyclops ... en 1.097371
1207 829.0 Chinatown ... en 1.081884
- NMF 알고리즘 영화 추천
movieId original_title ... original_language Estimate_Score
22094 3030.0 End of the World ... en 4.860103
6163 994.0 Straw Dogs ... en 4.830909
7234 923.0 Dawn of the Dead ... en 4.827061
459 2019.0 Hard Target ... en 4.820633
7057 3088.0 My Darling Clementine ... en 4.746116
... ... ... ... ... ...
3293 2383.0 L'Ours ... en 1.635867
11329 1975.0 The Grudge 2 ... en 1.601346
10998 806.0 The Omen ... en 1.577182
11324 3593.0 Dr. Cyclops ... en 1.217999
1207 829.0 Chinatown ... en 1.000000
- 변수 가중치 처럼 알고리즘마다 영화 추천이 다르다.
추천된 영화 포스터 시각화
TMDB OPEN API로 추천 영화 포스터 가져오기
from IPython.display import HTML
from IPython.display import display
import requests
import cv2
import urllib.request
import urllib
import tweepy
import time
- 우선 코랩에서 포스터가 정상적으로 나오는지 확인하기 위하여 인스톨들을 한다. 그리고 API로 값을 얻어와서 url로 이미지를 얻을 것이기 때문에 준비를 한다.
def display_recommendations(data):
api_key = '?api_key=8a98ba13f2855e4a5c4aae1af3e81974'
url = 'https://api.themoviedb.org/3/movie/'
urls = []
start = 0
data['imgUrl'] = ''
for i in range(len(data)):
mov_num = str(data['movieId'].iloc[i])
JSONcontent = requests.get(url + mov_num + api_key)
response = JSONcontent.json()
base_url = 'https://image.tmdb.org/t/p/original'
img_url = response['poster_path']
if img_url != None :
image_url = base_url + img_url
urls.append(image_url)
data['imgUrl'].iloc[i] = urls[i]
print(data['imgUrl'].iloc[i])
else:
image_url = "None"
urls.append(image_url)
data['imgUrl'].iloc[i] = 'None'
print(data['imgUrl'].iloc[i])
images = ''
for link in urls:
if link != '':
images += "<img style= 'width: 150px; margin: 1px; float: left; border: 1px solid black;' src= '%s'>" % link
display(HTML(images))
return data
- 우선 개인의 API키가 필요하기 때문에 TMDB에서 개인 API를 만들어 준비한다.
- 제이슨 형식으로 얻어온 포스터 주소를
url과 결합해서 값을 저장해야하기 때문에urls를 만든다. movieId를 기준으로 포스터를 불러온다.- 만약에
movieId로 조회했을 때 포스터 주소가None값을 넣고 값이 있으면 제이슨에서 얻은 포스터주소와url,api-key를 결합한 주소를 저장한다. - 정상적으로 포스터가 나오는지
display를 활용하여 코랩에서 확인한다.
display_recommendations 함수 실행
user_df665 = user_df665.head(12)
user_df665_poster = display_recommendations(user_df665)
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self._setitem_with_indexer(indexer, value)
https://image.tmdb.org/t/p/original/ow1esWlXoRPijAvR6GZQbv0uv9r.jpg
https://image.tmdb.org/t/p/original/V4kp32aLBx5Axj1FiIvE9U0CkR.jpg
https://image.tmdb.org/t/p/original/7AjzGYybwfndxnpApKXahQiq2Zy.jpg
https://image.tmdb.org/t/p/original/1nd4SsytVc96hy92g8NNVPD3mzf.jpg
https://image.tmdb.org/t/p/original/w0y7mNCiiHdyo05KlguqQS28Frn.jpg
https://image.tmdb.org/t/p/original/h6aVbUsiJB3Le1xrhyZXsXZOI3h.jpg
https://image.tmdb.org/t/p/original/84CweBYein3D8Aau0EidPvYaXln.jpg
https://image.tmdb.org/t/p/original/5yqs1MVlqdIg1DY5adC5jFx3d7j.jpg
https://image.tmdb.org/t/p/original/iDZoCrQUCkjcU8WtDH2g7QiU4fA.jpg
None
https://image.tmdb.org/t/p/original/fJDQDmJDiEzRROph0T1ace8oyNK.jpg
https://image.tmdb.org/t/p/original/sqelBKOEdYruo497Jx6SAC3jBMY.jpg
- 포스터 주소가
user_df665에 새로운 컬럼으로 저장된다.
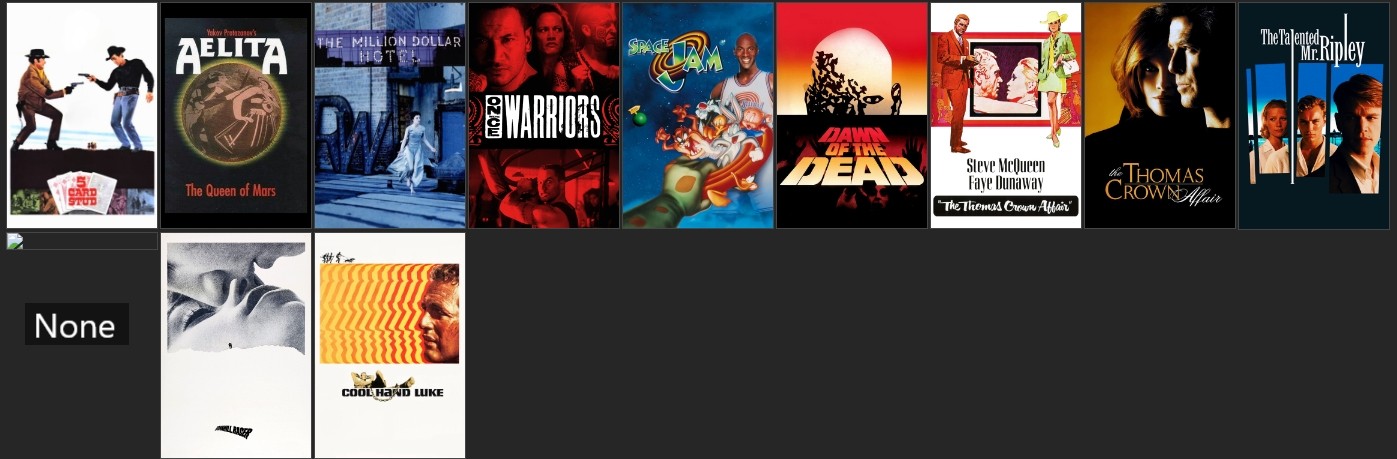
- 주소가 있는 영화는 정상적으로 포스터가 출력되고 주소가 없는 영화는 포스터가 표시되지 않는다.
user_df664 = user_df664.head(12)
user_df664_poster = display_recommendations(user_df664)
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self._setitem_with_indexer(indexer, value)
https://image.tmdb.org/t/p/original/fZXSwgZknp81vmciTb86rw0MejV.jpg
https://image.tmdb.org/t/p/original/5BSOIFbxwLILa8DE1jlhqG7Ravx.jpg
https://image.tmdb.org/t/p/original/iLWsLVrfkFvOXOG9PbUAYg7AK3E.jpg
https://image.tmdb.org/t/p/original/3fUgo5PBQqk0i7q4OoPiL5L8weW.jpg
https://image.tmdb.org/t/p/original/V4kp32aLBx5Axj1FiIvE9U0CkR.jpg
https://image.tmdb.org/t/p/original/vvevzdYIrk2636maNW4qeWmlPFG.jpg
https://image.tmdb.org/t/p/original/paI9Tmqm2cZG6xy4Tnjw3Ydjuw5.jpg
https://image.tmdb.org/t/p/original/keqscEvY0oZqbtiYf8odccmHlll.jpg
None
https://image.tmdb.org/t/p/original/kkhplxhm15IpCQxCi8Fl8flxjR4.jpg
https://image.tmdb.org/t/p/original/p9ue17zGuEZtMhAkdhUI1KNtEb1.jpg
https://image.tmdb.org/t/p/original/5QHW2USODuDfUahBX1qoOsR97Cr.jpg
- 포스터 주소가
user_df664에 새로운 컬럼으로 저장된다.

user_1_url = user_1.head(12)
user_1_ur12 = display_recommendations(user_1_url)
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
app.launch_new_instance()
https://image.tmdb.org/t/p/original/p9ue17zGuEZtMhAkdhUI1KNtEb1.jpg
https://image.tmdb.org/t/p/original/iLWsLVrfkFvOXOG9PbUAYg7AK3E.jpg
https://image.tmdb.org/t/p/original/7AjzGYybwfndxnpApKXahQiq2Zy.jpg
https://image.tmdb.org/t/p/original/84CweBYein3D8Aau0EidPvYaXln.jpg
https://image.tmdb.org/t/p/original/vvevzdYIrk2636maNW4qeWmlPFG.jpg
https://image.tmdb.org/t/p/original/5yqs1MVlqdIg1DY5adC5jFx3d7j.jpg
https://image.tmdb.org/t/p/original/kkhplxhm15IpCQxCi8Fl8flxjR4.jpg
https://image.tmdb.org/t/p/original/fZXSwgZknp81vmciTb86rw0MejV.jpg
https://image.tmdb.org/t/p/original/uHkmbxb70IQhV4q94MiBe9dqVqv.jpg
https://image.tmdb.org/t/p/original/5BSOIFbxwLILa8DE1jlhqG7Ravx.jpg
https://image.tmdb.org/t/p/original/TMlSiPuj9LymfwPiKFiRRnhkRq.jpg
https://image.tmdb.org/t/p/original/65iVwc0t5eTDhQJsddsR14uBuGr.jpg
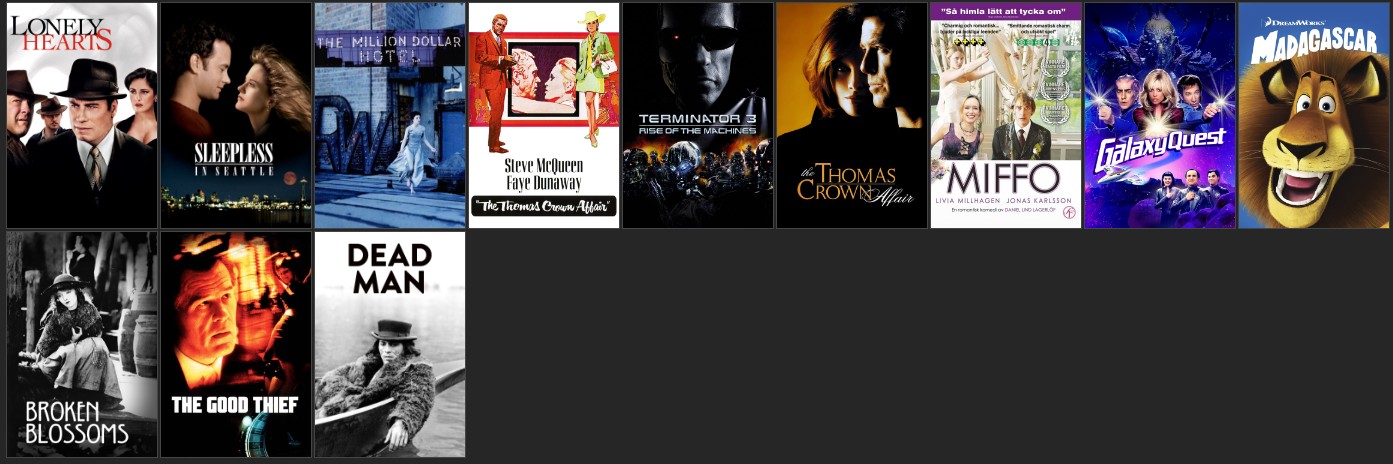
add_user_1_10 = add_user_1.head(12)
add_user_1_10_url = display_recommendations(add_user_1_10)
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
app.launch_new_instance()
https://image.tmdb.org/t/p/original/65iVwc0t5eTDhQJsddsR14uBuGr.jpg
https://image.tmdb.org/t/p/original/5yqs1MVlqdIg1DY5adC5jFx3d7j.jpg
https://image.tmdb.org/t/p/original/fZXSwgZknp81vmciTb86rw0MejV.jpg
https://image.tmdb.org/t/p/original/lhDn0yzCDkVCzHEtoLdASSLDHxn.jpg
https://image.tmdb.org/t/p/original/evj7SjxKHWXyH77r1QZN1alJGMR.jpg
https://image.tmdb.org/t/p/original/5BSOIFbxwLILa8DE1jlhqG7Ravx.jpg
https://image.tmdb.org/t/p/original/iLWsLVrfkFvOXOG9PbUAYg7AK3E.jpg
https://image.tmdb.org/t/p/original/iCIycswWbX1EDS6PYYBcR9ohrC.jpg
https://image.tmdb.org/t/p/original/iDZoCrQUCkjcU8WtDH2g7QiU4fA.jpg
https://image.tmdb.org/t/p/original/sXxvdg8kuFEUVvlLP02zOBu5yMF.jpg
https://image.tmdb.org/t/p/original/h6aVbUsiJB3Le1xrhyZXsXZOI3h.jpg
https://image.tmdb.org/t/p/original/jVititCfwaPXWDAZkjWkgmpcAkO.jpg

user_df_sum_relase1 = user_df_sum_relase.head(12)
user_df_sum_pop1 = user_df_sum_pop.head(12)
user_df_sum_lang1 = user_df_sum_lang.head(12)
user_df_sum_vote1 = user_df_sum_vote.head(12)
user_df_sum_relase3 = display_recommendations(user_df_sum_relase1)
user_df_sum_pop3 = display_recommendations(user_df_sum_pop1)
user_df_sum_lang3 = display_recommendations(user_df_sum_lang1)
user_df_sum_vote3 = display_recommendations(user_df_sum_vote1)
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
app.launch_new_instance()
https://image.tmdb.org/t/p/original/1nd4SsytVc96hy92g8NNVPD3mzf.jpg
https://image.tmdb.org/t/p/original/2149T34sq7akP1Mdm1LC7FJuImM.jpg
https://image.tmdb.org/t/p/original/6EODLN11HTX4l2cmakAhWIoJLF.jpg
https://image.tmdb.org/t/p/original/p9ue17zGuEZtMhAkdhUI1KNtEb1.jpg
https://image.tmdb.org/t/p/original/Rzaz2GSBJMnT9aYqzs715XoC4N.jpg
https://image.tmdb.org/t/p/original/uHkmbxb70IQhV4q94MiBe9dqVqv.jpg
https://image.tmdb.org/t/p/original/7AjzGYybwfndxnpApKXahQiq2Zy.jpg
https://image.tmdb.org/t/p/original/fZXSwgZknp81vmciTb86rw0MejV.jpg
https://image.tmdb.org/t/p/original/rwAdo5ugCcPm17A99f4iPPNhuZK.jpg
https://image.tmdb.org/t/p/original/kkhplxhm15IpCQxCi8Fl8flxjR4.jpg
https://image.tmdb.org/t/p/original/TMlSiPuj9LymfwPiKFiRRnhkRq.jpg
https://image.tmdb.org/t/p/original/frPAFd718R042GbMVWelLrk1h0D.jpg


https://image.tmdb.org/t/p/original/6EODLN11HTX4l2cmakAhWIoJLF.jpg
https://image.tmdb.org/t/p/original/1nd4SsytVc96hy92g8NNVPD3mzf.jpg
https://image.tmdb.org/t/p/original/8teH96d4Hcg1BWwCePXcuHrcYxw.jpg
https://image.tmdb.org/t/p/original/ow1esWlXoRPijAvR6GZQbv0uv9r.jpg
None
/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:21: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
https://image.tmdb.org/t/p/original/84CweBYein3D8Aau0EidPvYaXln.jpg
https://image.tmdb.org/t/p/original/jFpc9w3RmYeaOXMEfrtgshwVf4u.jpg
https://image.tmdb.org/t/p/original/7AjzGYybwfndxnpApKXahQiq2Zy.jpg
https://image.tmdb.org/t/p/original/p9ue17zGuEZtMhAkdhUI1KNtEb1.jpg
https://image.tmdb.org/t/p/original/paI9Tmqm2cZG6xy4Tnjw3Ydjuw5.jpg
https://image.tmdb.org/t/p/original/2149T34sq7akP1Mdm1LC7FJuImM.jpg
https://image.tmdb.org/t/p/original/6WZFYXMFFwNS0AmTd3deCLXjt10.jpg
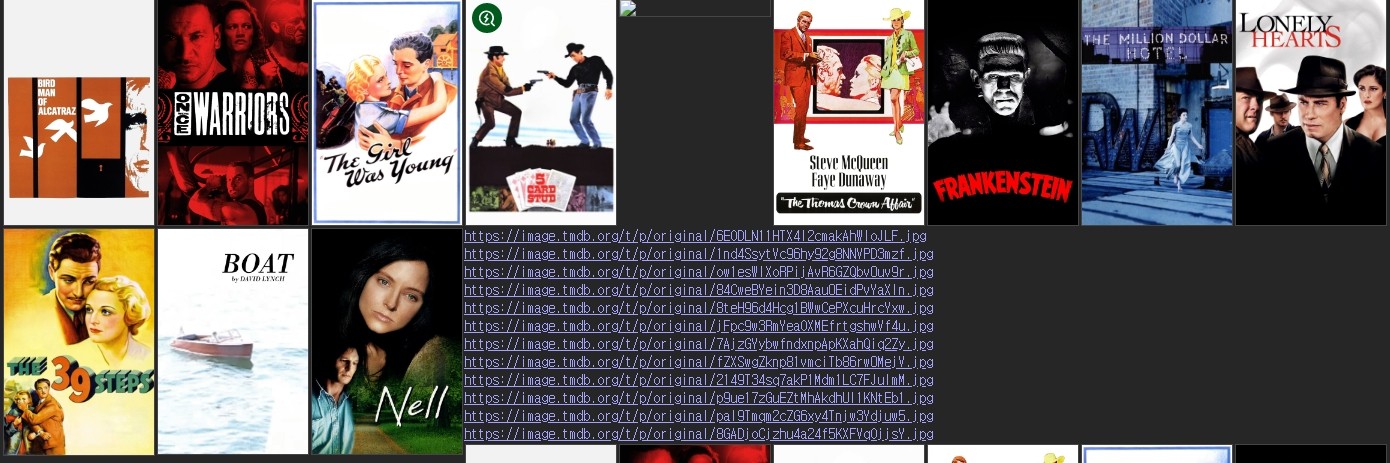
https://image.tmdb.org/t/p/original/6EODLN11HTX4l2cmakAhWIoJLF.jpg
https://image.tmdb.org/t/p/original/1nd4SsytVc96hy92g8NNVPD3mzf.jpg
https://image.tmdb.org/t/p/original/ow1esWlXoRPijAvR6GZQbv0uv9r.jpg
https://image.tmdb.org/t/p/original/84CweBYein3D8Aau0EidPvYaXln.jpg
https://image.tmdb.org/t/p/original/8teH96d4Hcg1BWwCePXcuHrcYxw.jpg
https://image.tmdb.org/t/p/original/jFpc9w3RmYeaOXMEfrtgshwVf4u.jpg
https://image.tmdb.org/t/p/original/7AjzGYybwfndxnpApKXahQiq2Zy.jpg
https://image.tmdb.org/t/p/original/fZXSwgZknp81vmciTb86rw0MejV.jpg
https://image.tmdb.org/t/p/original/2149T34sq7akP1Mdm1LC7FJuImM.jpg
https://image.tmdb.org/t/p/original/p9ue17zGuEZtMhAkdhUI1KNtEb1.jpg
https://image.tmdb.org/t/p/original/paI9Tmqm2cZG6xy4Tnjw3Ydjuw5.jpg
https://image.tmdb.org/t/p/original/8GADjoCjzhu4a24f5KXFVqOjjsY.jpg

https://image.tmdb.org/t/p/original/1nd4SsytVc96hy92g8NNVPD3mzf.jpg
https://image.tmdb.org/t/p/original/7AjzGYybwfndxnpApKXahQiq2Zy.jpg
None
https://image.tmdb.org/t/p/original/3fUgo5PBQqk0i7q4OoPiL5L8weW.jpg
https://image.tmdb.org/t/p/original/ow1esWlXoRPijAvR6GZQbv0uv9r.jpg
https://image.tmdb.org/t/p/original/zEwNZItImh1uz5kQuHXenamK3N3.jpg
https://image.tmdb.org/t/p/original/vvevzdYIrk2636maNW4qeWmlPFG.jpg
https://image.tmdb.org/t/p/original/pZUBI77RMu652QmtWL9RBWF1uO6.jpg
https://image.tmdb.org/t/p/original/84CweBYein3D8Aau0EidPvYaXln.jpg
https://image.tmdb.org/t/p/original/r4F4tsU0Ajeh9ZYUkWOJSYmioj7.jpg
https://image.tmdb.org/t/p/original/uHkmbxb70IQhV4q94MiBe9dqVqv.jpg
https://image.tmdb.org/t/p/original/p9ue17zGuEZtMhAkdhUI1KNtEb1.jpg

als_recomend1 = als_recomend.head(12)
svd_recomend1 = svd_recomend.head(12)
slope_recomend1 = slope_recomend.head(12)
nmf_recomend1 = nmf_recomend.head(12)
als_recomend_poster = display_recommendations(als_recomend1)
svd_recomend_poster = display_recommendations(svd_recomend1)
slope_recomend_poster = display_recommendations(slope_recomend1)
nmf_recomend_poster = display_recommendations(nmf_recomend1)
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
app.launch_new_instance()
https://image.tmdb.org/t/p/original/iLWsLVrfkFvOXOG9PbUAYg7AK3E.jpg
https://image.tmdb.org/t/p/original/p9ue17zGuEZtMhAkdhUI1KNtEb1.jpg
https://image.tmdb.org/t/p/original/7AjzGYybwfndxnpApKXahQiq2Zy.jpg
https://image.tmdb.org/t/p/original/84CweBYein3D8Aau0EidPvYaXln.jpg
https://image.tmdb.org/t/p/original/vvevzdYIrk2636maNW4qeWmlPFG.jpg
https://image.tmdb.org/t/p/original/5yqs1MVlqdIg1DY5adC5jFx3d7j.jpg
https://image.tmdb.org/t/p/original/fZXSwgZknp81vmciTb86rw0MejV.jpg
https://image.tmdb.org/t/p/original/h6aVbUsiJB3Le1xrhyZXsXZOI3h.jpg
https://image.tmdb.org/t/p/original/5BSOIFbxwLILa8DE1jlhqG7Ravx.jpg
https://image.tmdb.org/t/p/original/65iVwc0t5eTDhQJsddsR14uBuGr.jpg
https://image.tmdb.org/t/p/original/6WZFYXMFFwNS0AmTd3deCLXjt10.jpg
https://image.tmdb.org/t/p/original/V4kp32aLBx5Axj1FiIvE9U0CkR.jpg

https://image.tmdb.org/t/p/original/ow1esWlXoRPijAvR6GZQbv0uv9r.jpg
https://image.tmdb.org/t/p/original/84CweBYein3D8Aau0EidPvYaXln.jpg
https://image.tmdb.org/t/p/original/3fUgo5PBQqk0i7q4OoPiL5L8weW.jpg
https://image.tmdb.org/t/p/original/6WZFYXMFFwNS0AmTd3deCLXjt10.jpg
https://image.tmdb.org/t/p/original/paI9Tmqm2cZG6xy4Tnjw3Ydjuw5.jpg
https://image.tmdb.org/t/p/original/h6aVbUsiJB3Le1xrhyZXsXZOI3h.jpg
https://image.tmdb.org/t/p/original/5QHW2USODuDfUahBX1qoOsR97Cr.jpg
https://image.tmdb.org/t/p/original/5yqs1MVlqdIg1DY5adC5jFx3d7j.jpg
https://image.tmdb.org/t/p/original/uHkmbxb70IQhV4q94MiBe9dqVqv.jpg
https://image.tmdb.org/t/p/original/zN6t0CL3Obs4oMQkYhnTBi6QYiM.jpg
https://image.tmdb.org/t/p/original/w0y7mNCiiHdyo05KlguqQS28Frn.jpg
https://image.tmdb.org/t/p/original/3bdfN2gosYSxpHBAXPkAhxkUJFr.jpg


https://image.tmdb.org/t/p/original/2GDdW84XSX3BYMJ9tmnFkZOGJyB.jpg
https://image.tmdb.org/t/p/original/5vpUjm2wnR2cyrqEhpJTsu1pfhg.jpg
https://image.tmdb.org/t/p/original/utpUn9TdBIx6x2QX91YhYzFZxg1.jpg
https://image.tmdb.org/t/p/original/k8xZQCbp7rULhBhk03Y2x21jAuy.jpg
https://image.tmdb.org/t/p/original/2gJLSn3ipt3gDRfwOxXRraH6YtM.jpg
https://image.tmdb.org/t/p/original/2ApifgYnfdJUSmCKzTBrWOYYWsn.jpg
https://image.tmdb.org/t/p/original/p9ue17zGuEZtMhAkdhUI1KNtEb1.jpg
https://image.tmdb.org/t/p/original/kMD7UJdvMxZL4UT3jAyZDpisJ9F.jpg
https://image.tmdb.org/t/p/original/oedFtX9hZZWpD7L5wkD0WxSteY2.jpg
https://image.tmdb.org/t/p/original/toaY9CoMAy37QNv8HbbUqWS4X1Q.jpg
https://image.tmdb.org/t/p/original/c4wrCYEgEtLXxoyEZf4pBl6XD4V.jpg
https://image.tmdb.org/t/p/original/6WZFYXMFFwNS0AmTd3deCLXjt10.jpg
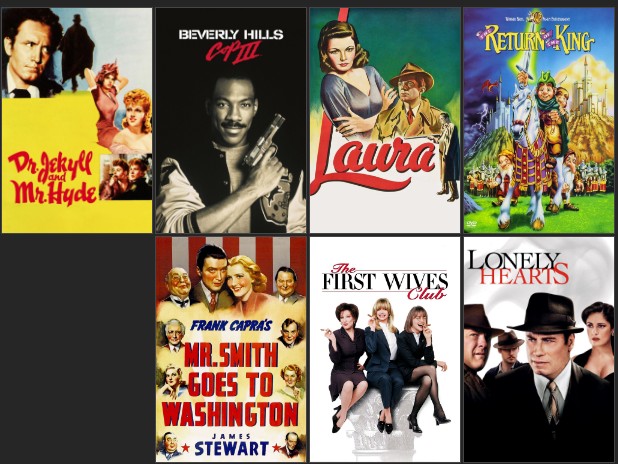

https://image.tmdb.org/t/p/original/kMD7UJdvMxZL4UT3jAyZDpisJ9F.jpg
https://image.tmdb.org/t/p/original/yigkfHE1OhkxPPrjrV78Y9ibGEk.jpg
https://image.tmdb.org/t/p/original/h6aVbUsiJB3Le1xrhyZXsXZOI3h.jpg
https://image.tmdb.org/t/p/original/x9HfOKWAB506jJVWo0z848SKDML.jpg
https://image.tmdb.org/t/p/original/hNRPIgWfx5EVG1DtNSFZGEnF6AJ.jpg
https://image.tmdb.org/t/p/original/mavrhr0ig2aCRR8d48yaxtD5aMQ.jpg
https://image.tmdb.org/t/p/original/3m9N28O67WLL7wKNO08dU7CaNdu.jpg
https://image.tmdb.org/t/p/original/kkhplxhm15IpCQxCi8Fl8flxjR4.jpg
https://image.tmdb.org/t/p/original/xzRC2QeLKhv6PM2vXUKG4jAhQCi.jpg
https://image.tmdb.org/t/p/original/5h25Ea04E5lRUqP7cC0nbT85vkt.jpg
https://image.tmdb.org/t/p/original/p9ue17zGuEZtMhAkdhUI1KNtEb1.jpg
https://image.tmdb.org/t/p/original/toaY9CoMAy37QNv8HbbUqWS4X1Q.jpg
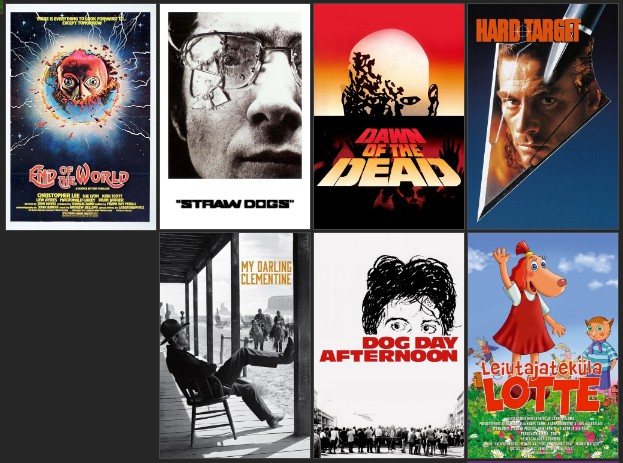
이렇게 포스터가 정상적으로 나오는 것을 확인하였다. 이제 데이터를 저장하고 Power Bi로 시각화를 한다.
user_df665_poster2 = user_df665_poster.to_csv('../content/drive/My Drive/user_df665_poster.csv')
user_df664_url_data = user_df664_poster.to_csv('../content/drive/My Drive/user_df664_poster.csv')
user_1_ur12.to_csv('../content/drive/My Drive/user_1_url.csv')
add_user_1_10_url.to_csv('../content/drive/My Drive/add_user_1_10_url.csv')
user_df_sum_relase4 = user_df_sum_relase3.to_csv('../content/drive/My Drive/user_df_sum_relase_Url.csv')
user_df_sum_pop4 = user_df_sum_pop3.to_csv('../content/drive/My Drive/user_df_sum_pop_Url.csv')
user_df_sum_lang4 = user_df_sum_lang3.to_csv('../content/drive/My Drive/user_df_sum_lang_Url.csv')
user_df_sum_vote4 = user_df_sum_vote3.to_csv('../content/drive/My Drive/user_df_sum_vote_Url.csv')
als_recomend_poster1 = als_recomend_poster.to_csv('../content/drive/My Drive/als_recomend_poster.csv')
svd_recomend_poster1 = svd_recomend_poster.to_csv('../content/drive/My Drive/svd_recomend_poster.csv')
slope_recomend_poster1 = slope_recomend_poster.to_csv('../content/drive/My Drive/slope_recomend_poster.csv')
nmf_recomend_poster1 = nmf_recomend_poster.to_csv('../content/drive/My Drive/nmf_recomend_poster.csv')